Seguindo a ideia do post anterior, sou fã do Top Gear UK e, para a minha tristeza, nenhum serviço de streaming brasileiro tem a série no catálogo. Após ripar os DVDs, extrair as legendas e traduzi-las para português com o modelo NLLB-200, o resultado foi razoável, mas longe do ideal, pois traduziu "Car Dealers" como "Traficante de carros" e cometeu outros erros do gênero.
Decidi então usar outro modelo que traria resultados superiores: o Qwen2.5
Neste guia, vou mostrar como traduzi todas as temporadas de Top Gear UK usando minha GPU com o modelo QWEN2.5 e os resultados.


O que você vai precisar
Hardware
- GPU NVIDIA (recomendado: RTX 3060 ou superior com pelo menos 12GB VRAM).
- Funciona com CPU também, mas será muito mais lento.
- 20-50GB de espaço livre em disco para o modelo.
Software
- Windows, Linux ou macOS
- Este tutorial cobrirá apenas o Windows. Para Linux e macOS, os passos são similares, apenas ajuste os comandos do terminal conforme seu sistema.
- Python 3.12
- Ollama (gerenciador de modelos LLM locais)
- CUDA (se usar GPU NVIDIA)
Passo 1: Instalar o Ollama
O Ollama é um gerenciador de modelos de IA que roda localmente, pense nele como um "Docker para modelos de linguagem".
- Baixe o instalador: ollama.com/download/windows
- Execute o instalador
- O Ollama iniciará automaticamente (ícone na bandeja do sistema)
Verificando a instalação do Ollama
Abra o terminal/prompt de comando e execute:
ollama --versionSe aparecer a versão, está tudo certo!
Passo 2: Escolher e baixar o modelo
Aqui está o pulo do gato: nem sempre o modelo maior é melhor para tradução.
Modelos testados e recomendados
| Modelo | VRAM | Velocidade | Qualidade | Recomendado para |
|---|---|---|---|---|
| qwen2.5:7b | ~5GB | Muito rápido | Boa | GPUs entry-level (GTX 1660, RTX 3050) |
| qwen2.5:14b | ~12GB | Rápido | Excelente | RTX 3060/4060 ou melhor |
| qwen2.5:32b | ~23GB | Moderado | Excelente | RTX 4090, A6000 |
Minha recomendação: Qwen2.5 14B para a maioria dos casos (usei o qwen2.5:32b pois rodei na minha 4090).
Nesse tutorial vamos usar o modelo 32b.
Tempo estimado por arquivo com o modelo 32b (4090):
Com a 4090 + Qwen2.5:32B + Batch 10:
| Tamanho do arquivo | Blocos | Tempo estimado |
|---|---|---|
| Episódio curto (20min) | ~400 | 8-12 minutos |
| Episódio médio (40min) | ~800 | 16-22 minutos |
| Episódio longo (60min) | ~1200 | 25-35 minutos |
| Filme (2h) | ~2500 | 50-70 minutos |
Baixando o modelo
Abra o terminal/prompt de comando e execute:
ollama pull qwen2.5:32bIsso vai baixar o modelo (~23GB), aguarde o download terminar.
Você pode baixar outros modelos se preferir, como: qwen2.5:7b, qwen2.5:14b ou qwen2.5:32b (utilizado no exemplo).
Vamos usar o Qwen2.5:32B porque:
- Tem 32 bilhões de parâmetros (mais pesado)
- Excelente para tradução de legendas
- Funciona bem na RTX 4090 (usa ~23GB VRAM)
- Boa velocidade vs qualidade
Testando o modelo
Com o Ollama aberto:
ollama run qwen2.5:32b "Traduza para português: Hello, how are you?"Se respondeu em português, está funcionando! Pressione Ctrl + C para sair.
Passo 3: Instalar o Python 3.12
- Acesse: python.org/downloads
- Clique em "Download Python 3.12.x"
- Aguarde o download do instalador (
python-3.12.x-amd64.exe) - Execute o instalador do python.
IMPORTANTE: Marque a caixa "Add Python to PATH" na tela inicial
Verificando a instalação do Python
Abra o terminal/prompt de comando e execute:
python --versionSe aparecer a versão, está tudo certo!
Passo 4: Preparar o Script de Tradução
Será necessário criar duas pastas, uma para as legendas no idioma original e outra para as legendas traduzidas.
Mova todas as legendas que serão traduzidas para o diretório correspondente criado acima.
Baixe o script de tradução no github:
https://github.com/TGuerreiro/scripts/blob/main/srt_translator_qwen25.py
Instalar biblioteca Python
Abra o terminal/prompt de comando na pasta onde salvou o script e execute:
pip install requestsPasso 5: Executar a Tradução
Verifique se o Ollama está rodando! Caso não estiver, abra ele pelo menu iniciar.
Acesse a pasta onde você salvou o script usando o terminal/prompt de comando e execute o comando abaixo, substituindo pelos caminhos dos seus diretórios:
python srt_translator_qwen25.py <diretório_legendas_originais> <diretório_legendas_traduzidas>Exemplo prático:
python srt_translator_qwen25.py C:\legendas\originais C:\legendas\traduzidasPersonalizando a Execução
Você também pode especificar o modelo e a URL da API do Ollama:
python srt_translator_qwen25.py C:\legendas\originais C:\legendas\traduzidas --model qwen2.5:7bArgumentos da Linha de Comando:
input- Obrigatório. Pasta com legendas a serem traduzidasoutput- Obrigatório. Pasta onde serão salvas as legendas traduzidas-m, --model- Opcional. Seleciona o modelo Qwen 2.5 a ser utilizado. Se não especificado, o script utilizaráqwen2.5:32bcomo padrão.
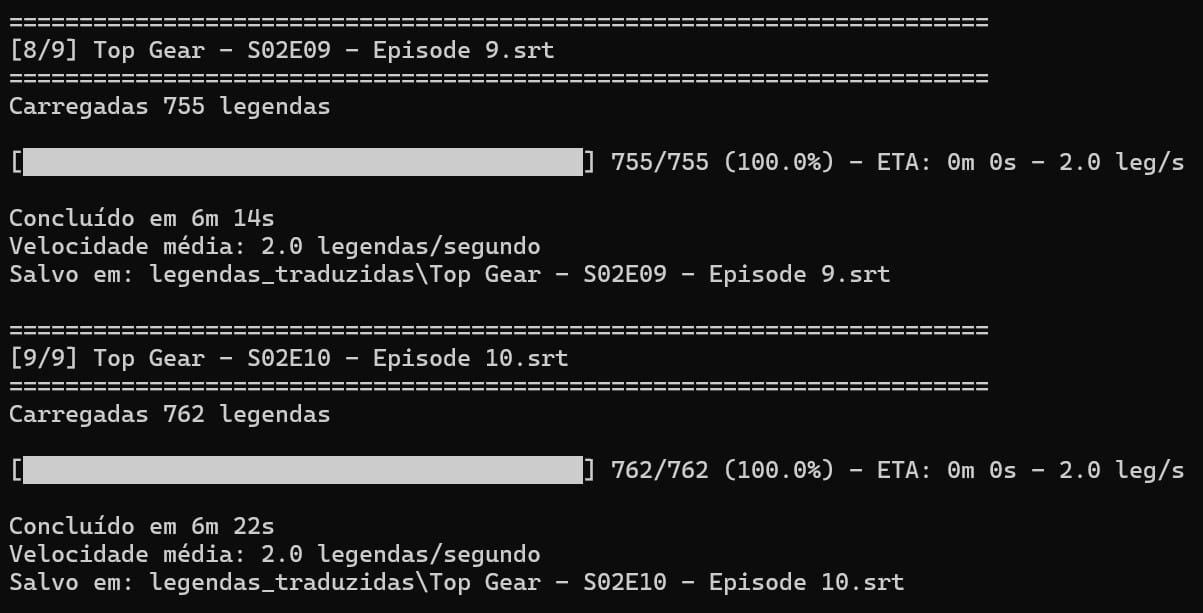
Acompanhar o progresso
Você verá uma saída assim:
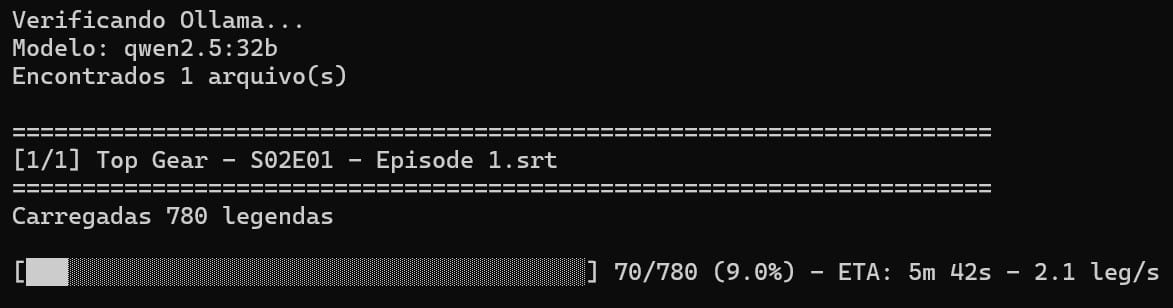
Você pode parar o processo a qualquer momento digitando Ctrl + CO que está acontecendo:
- O script está processando cada arquivo
- A barra mostra o progresso em tempo real
- O "ETA" mostra tempo estimado restante
- Sua GPU está trabalhando a todo vapor!
Monitorar uso da GPU (opcional mas recomendado)
Para ver sua GPU trabalhando, abra outro terminal/prompt de comando e digite:
nvidia-smiIsso mostrará estatísticas da GPU
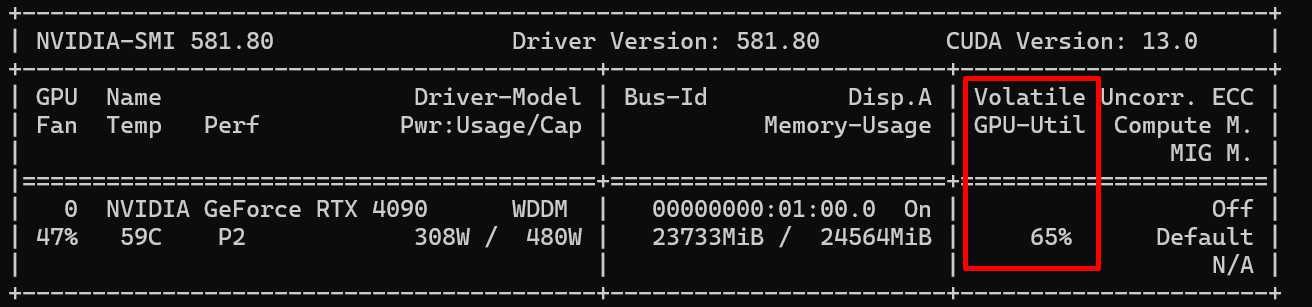
O que você deve ver:
- GPU-Util: 60-90% (GPU sendo bem utilizada)
- Memory-Usage: ~23GB (modelo carregado na 4090)
- Power: 280-350W (processamento intenso)
- Temp: 60-75°C (normal sob carga)
Se o GPU-Util estiver em 0-10%, algo está errado.
Suas legendas traduzidas estarão na pasta que você informou ao executar o script.
Todo o script está otimizado para a GPU RTX 4090 e para a série Top Gear UK. Para outros conteúdos, edite o prompt na linha 114 ajustando o contexto. Por exemplo, para traduzir um documentário científico, altere para: "You are translating scientific documentary subtitles..."
Resultados








Dicas Finais
- Sempre faça backup das legendas originais antes de começar
- Teste com 1 arquivo primeiro para validar a qualidade
- Assista alguns minutos do resultado antes de processar tudo
- Deixe a GPU trabalhar em paz, não jogue ou use programas pesados durante a tradução
- Monitore a temperatura, se passar de 80°C consistentemente, melhore a ventilação
- Traduza de madrugada se tiver tarifa de energia diferenciada
FAQ
E se eu não tiver RTX 4090?
Você pode usar o modelo menor (14B ou 7B) que funcionam com menos VRAM. RTX 3060/4060 com 12GB conseguem rodar o 14B tranquilamente.
Funciona para outros idiomas?
R: Sim! Basta mudar o prompt no script. O Qwen suporta dezenas de idiomas.
Preciso de internet?
Apenas para baixar o modelo inicial. Depois disso, tudo é offline.
A tradução é perfeita?
Não existe tradução perfeita, mas a qualidade é equivalente a 90-95% de precisão. Ocasionalmente pode errar gírias muito específicas.
Posso interromper e continuar depois?
Sim. O script processa arquivo por arquivo. Se interromper Ctrl + C, os arquivos já traduzidos estarão salvos. Basta executar novamente que ele pulará os já existentes.
Quanto tempo leva para traduzir uma temporada completa?
Depende do número de episódios e duração. Em média, 10 episódios de 40min cada = 1h20 a 2h (dependendo da GPU e quantidade de blocos de legendas por vez).
Script Completo
O script está disponível no github: